
A Custom Splunk Command Integrating ChatGPT? Yes, It's Epic! (February 2023)
This article was authored by Brian Bates of RHONDOS.
I have been watching the OpenAI ChatGPT phenomenon since it came across my Twitter feed, and I tried to be one of those first 1 million users. Spoiler alert, ChatGPT couldn’t tell me if I was one of the first million, but I believe I am! I signed up as fast as I could to begin a dialogue with the #artificialintelligence. It’s an incredible breakthrough and the speed at which ChatGPT is disrupting workflow and optimizing human behavior is inspiring. I don’t fall into the camp of doom and gloom because I believe rotation in technology has always been a great benefit to humanity.
Having been in the Splunk big data analytics space across multiple industry verticals, I’m acutely familiar with the problem of new users ramping up to a new solution. User adoption was a challenge for me when I was a customer, and it remains a challenge for many of my clients spanning both ends of the Fortune 2000. What if there was a Splunk command for ChatGPT? Game on.
The first thing to do was to read the docs and scaffold up the API framework. OpenAI makes it easy to generate a key – snag one and save it to your preferred secrets manager. You can still get in with a free research account at the time of this writing, but the space is changing rapidly.
The API is straightforward and easy to work with at the terminal. I didn’t expect to be able to select which model or engine to use. With the model parameter, you can choose to use an older version of Davinci “text-davinci-002”. OpenAI prices the API on a token unit of measurement, somewhat mathematically related to the number of words generated. Currently, the pricing is 1,000 tokens for about 750 words. In addition to the versions of Davinci, there are other models that can be used such as Ada (which is the fastest), Babbage, and Curie, all at different price points:
curl https://api.openai.com/v1/completions
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"model": "text-davinci-003",
"prompt": "Say this is a test",
"max_tokens": 7,
"temperature": 0
}'\I highly recommend trying out multiple models if for no other reason than to see just how epic Davinci is. There can be a significant cost advantage to using an older model but it’s somewhat coarse in response to the industry-specific questions I was asking.
For example, I asked Davinci 2 and Davinci 3 the same SAP-specific question, and here are the results.

Comparison of Resonse between Davinci 2 (first response) and Davinci 3 (second response)
No one using Splunk for SAP data is getting any value out of Davinci 2 for this use case so I’m still exploring how to tune model usage within the add-on. The response from what SM20 is used for is simply too generic to be of any help. However, the depth of the answer and clarity of the message from Davinci 3 is just wild.
For creating a custom Splunk command, I refer heavily to Splunk’s developer documentation. It’s really good and there are plenty of examples on their GitHub to draw inspiration from. Creating a command is (almost) simply writing a Python script for what you want to do and wrapping it in Splunk’s SDK for the type of command you are executing. That may be a transforming command, generating command, or others. Here’s an example of creating a class (I used this for testing) for this use case after which you’ll need to define the GeneratingCommand and dispatch from splunklib:
class openCommand()
def __init__(self, engine, prompt):
self.engine = engine
self.prompt = prompt
# Load data from REST API
def open(self):
record = {}
# Set the API key for OpenAI
openai.api_key = "<TOKEN>"
# Use the OpenAI API to generate a response
response = openai.Completion.create(
engine = self.engine,
prompt = self.prompt,
max_tokens = 1024,
n = 1,
stop = None,
temperature = 0.5,
)
record = {'response': response["choices"][0]["text"]}
print(record):
search = openCommand("text-davinci-003", "What is the SAP transaction SM20 used for?")Within the command configuration, you’ll be able to define the options you are passing from the SPL query into the operation. For this prototype, I’ll be passing in the prompt parameter but sticking with default values for engine, max_tokens, temperature, etc.
Once you are finished with the Python script, you need to tell Splunk this is a command that can be called from SPL or customer alert actions. There are several .conf files to author which are mandatory but then one that makes the command really shine in the UI.
First, create commands.conf in the /default folder and add the stanza for your command. Make sure to set chunked = true and python.version = python3.

Example commands.conf configuration
In the same /default directory, create searchbnf.conf and give the users some guidance! There are many options here including description, syntax usage, and even examples.

Example searchbnf.conf configuration
Now when the docs run out, and you try to run this, you’ll find that there are a number of dependencies that you don’t realize are so important until running the commands in Splunk. You’ll need to import openai Python module and this is where the “best practices” diverge by how you’ll be maintaining this custom command. If you do a search, you may find some communities recommending running pip in the site-packages local to Splunk – don’t! Even if nothing breaks, you just blew up your upgrade path.
For this overnight prototype, I elected to place the required modules in the /bin directory of the app. For my application, I needed aiohttp and aiosignal in addition to the openai module. These are usually installed automatically when using pip in you environment, but we’re on a manual process at the moment.
I also ran into an issue with Splunk shipping with Python 3.7 which I didn’t really think about. Consistently, I was getting ModuleNotFoundErrors as I was troubleshooting importing openai so I got a little lazy in viewing the logs. After a coffee refresh, I went through the search.log, I found the Traceback error where a call to typing failed. What’s interesting here is that the hdrs.py file has an if statement to refer typing if Python version 3.8+ is used else import from typing_extensions. My local environment is 3.9 and so typing was at the ready. After some investigation, I discovered Splunk Python 3.7 does not include the necessary object for this. I ran over to pypi and snagged the latest download for typing_extensions which provides some backwards compatibility for older versions of Python. With Splunk using a version of Python so old and without its site-packages including this backwards compatibility, I had to add it to the /bin folder and import the module on the fly.
Now for the fun. Directly in the Splunk search bar, you would enter | followed by the command “open” and then pass the parameters such as:
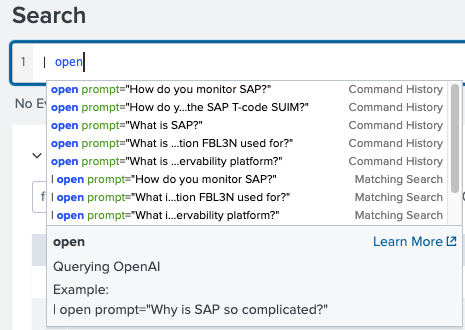
Configuration to support users with
examples at time of search
The result? Pretty awesome. I’ll let the screenshot do the talking.

Custom "open" command in action with response from ChatGPT
There is obviously still much to do in terms of packaging and arguably more importantly, enhancing the contextual filter of the prompts. Ideally, this add-on will improve tool adoption because it’s solving problems – not asking for the Seahawk's score.
But honestly, tl;dr? Just ask ChatGPT. It’s likely to write more succinctly and is definitely more accurate with the code. Happy hacking!
Disclaimer: all opinions and language/spelling/code errors are my own.
Brian Bates is the Director of Solutions Architecture at RHONDOS.